


.svg)

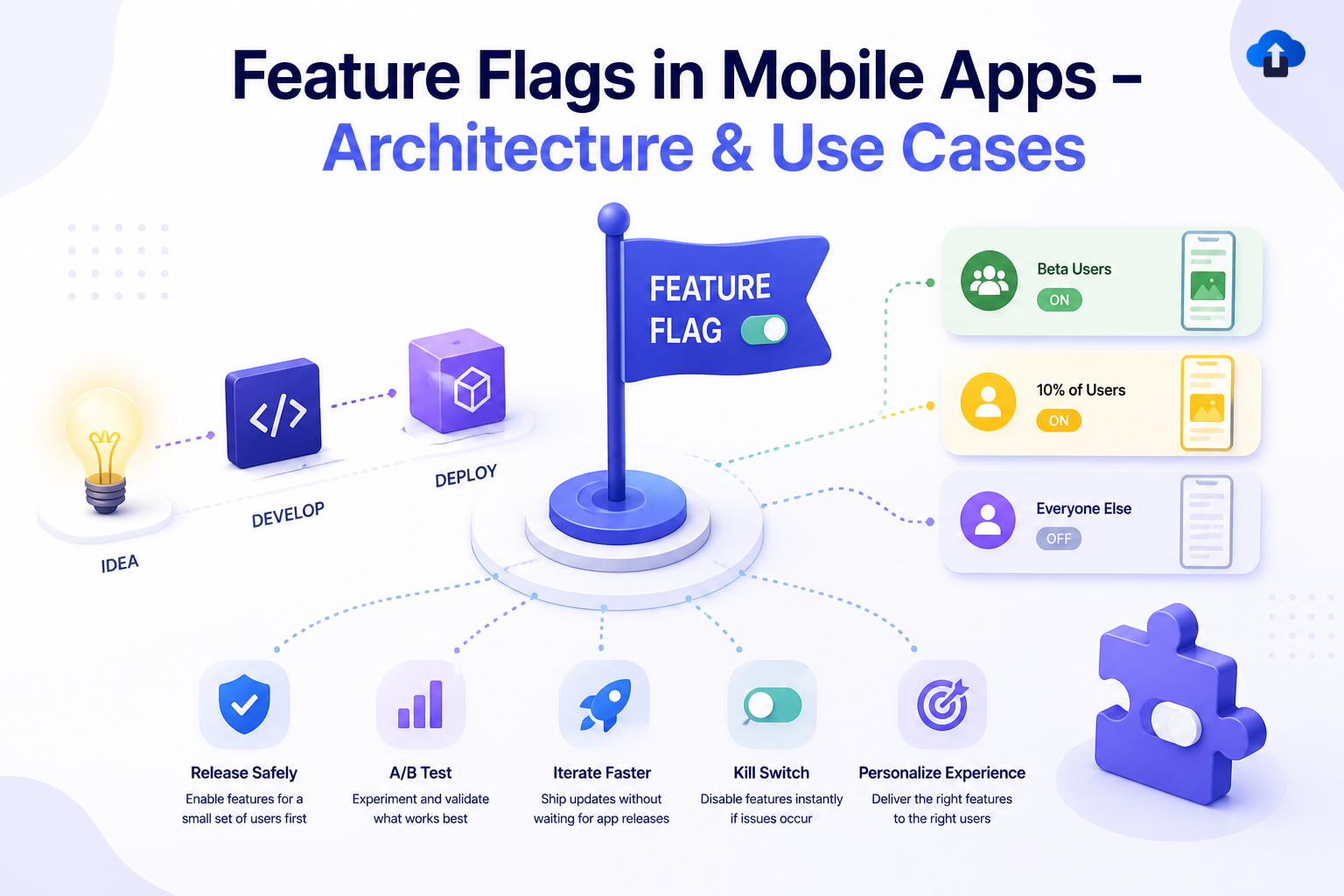
Feature flags — also known as feature toggles or feature switches — have matured from a simple release-gating trick into a core architectural primitive in modern mobile engineering. At their most fundamental, a feature flag is a conditional branch in code that is driven not by a compile-time constant, but by a runtime configuration value that can be changed without redeploying the application. This deceptively simple concept unlocks an entirely different way of thinking about software delivery: instead of treating a release as an atomic event, teams can decouple the act of deploying code from the act of activating it.
Mobile development amplifies the need for this capability in ways that server-side engineering does not fully share. A backend service can be updated and rolled back in minutes. A mobile app, once released to the App Store or Google Play, is in the wild — subject to review timelines, user update adoption curves, and fragmented OS versions. A critical regression that slips into a production release cannot be patched instantly. Feature flags change this calculus. They give mobile teams a genuine kill switch for problematic code, a mechanism for staged rollouts to percentage-based user cohorts, and a clean way to conduct A/B experiments without spinning up parallel release branches.
This article is a comprehensive technical examination of feature flags for mobile applications — covering the foundational concepts, system architecture, implementation strategies, advanced patterns, and the production realities that teams encounter at scale. Whether you are building a feature flag system from scratch or evaluating a third-party solution, the goal here is to give you the engineering vocabulary and structural thinking to make those decisions with clarity.
Foundational Concept
A feature flag is, at its core, a named boolean — or a more expressive configuration value — that is evaluated at runtime to decide which code path to execute. The pattern was documented formally by Martin Fowler under the term 'feature toggles', but mobile engineers have been applying the concept informally for years through platform-specific mechanisms like remote config endpoints and build flavors. The key evolution in the last several years is the shift from ad-hoc conditional checks to structured systems that manage flag lifecycle, targeting rules, evaluation context, and audit history.
There is an important taxonomy to understand. Release flags are short-lived and gate features until they are ready for all users. Experiment flags power A/B and multivariate tests. Operational flags are longer-lived switches that control behavior in production — like enabling a fallback payment provider or toggling a rate limiter. Permission flags control feature access based on subscription tier or user segment. Each type has different lifecycle expectations, different evaluation logic, and different ownership patterns within an engineering organization. Conflating them leads to the most common feature flag antipatterns: flags that should have been retired years ago sitting as permanent conditionals in the codebase.
The evolution of feature flag tooling in mobile mirrors the broader shift toward continuous delivery. Early mobile teams used server-driven UI configuration or simple remote JSON files. As platforms matured and CI/CD pipelines shortened release cycles, teams needed more granular targeting, more reliable evaluation semantics, and better observability. Today, full-featured SDKs and managed services handle the heavy lifting — but understanding the substrate they are built on remains essential for diagnosing problems and designing systems that survive scale.
Key flag categories to understand:
- Release flags — temporary gates for incomplete or in-progress features
- Experiment flags — drive A/B tests and multivariate experiments
- Operational flags — long-lived switches for runtime behavior and fallbacks
- Permission flags — control access by user tier, segment, or region
- Kill switches — emergency override flags to disable a feature instantly
Why It Matters in Modern Mobile Development
The mobile release pipeline has unique constraints that make feature flags structurally more valuable than in other deployment contexts. App store review cycles — while generally faster than they were five years ago — still introduce latency between a code commit and a user receiving the change. Even with expedited review, teams cannot guarantee a fix reaches all users within hours. This asymmetry between deploy speed and user adoption means that mobile teams carry risk in a way backend teams do not. A feature flag system is the primary risk-mitigation lever available after a build is signed and submitted.
There is also the dimension of user diversity. A single mobile app may run across dozens of OS versions, multiple device form factors, and carrier configurations that affect network behavior. Progressive rollouts — enabling a flag for 1% of users, monitoring error rates and performance metrics, then expanding the cohort — give teams an empirical signal before a feature reaches the entire install base. This is not just risk reduction; it is a feedback mechanism that makes mobile releases genuinely data-driven.
From a developer experience perspective, feature flags enable trunk-based development at scale. Engineers can merge incomplete features behind a flag without creating long-running feature branches that accumulate merge debt. Product managers can gate features for specific markets or beta users without requiring a separate binary. QA teams can test unreleased features on production environments. These workflow benefits compound over time and represent some of the highest-leverage improvements a mobile engineering organization can make to its development process.
Core organizational benefits:
- Decoupled deployment from feature activation — ship code independently of feature release dates
- Staged rollouts — progressively expand user cohorts with observability at each step
- Instant kill switches — disable a production feature within seconds, no re-review required
- Trunk-based development — merge incomplete work to main without shipping it to users
- Experiment infrastructure — run controlled experiments without parallel binary builds
Architecture & System Design Breakdown
A production-grade feature flag system for mobile has four primary layers: the flag store, the evaluation engine, the SDK layer, and the management interface. These layers communicate through well-defined contracts and must be designed with offline resilience in mind — mobile apps operate in degraded network conditions regularly, and a feature flag evaluation must never block on a network call in the critical path of the application.
The flag store is the source of truth for flag definitions, targeting rules, and rollout configurations. It is typically a highly available key-value or document store backed by a CDN for low-latency global reads. The evaluation engine sits between the store and the SDK: it takes a flag key, an evaluation context (user ID, app version, locale, device type, custom attributes), and the targeting ruleset, and returns a resolved value. The evaluation engine should be deterministic — the same context should always produce the same flag value — and this determinism is especially important for experiment assignment consistency.
The mobile SDK is the client-side component that bootstraps flag evaluation, manages a local cache, handles network polling or streaming updates, and exposes a simple API to application code. Critically, the SDK must initialize from a bundled fallback configuration so that the app is never in a state where flags are undefined. This bootstrapping pattern — also called default-first initialization — is one of the most important architectural decisions in mobile flag systems because it determines behavior in the first session after install and in all offline scenarios.
System Architecture Overview

The management console sits above the flag store and provides the interface through which product managers, engineers, and release operators configure flags. A well-designed console includes an audit log that records every flag state change with a timestamp and author — this becomes invaluable for incident postmortems when diagnosing whether a flag change correlates with a production spike.
Implementation Deep Dive
Implementing a feature flag system in a mobile app is not simply a matter of wrapping conditionals around feature code. The implementation must account for initialization order, threading behavior, caching strategy, and the contract between the flag abstraction layer and the rest of the application. Apps that skip this architectural discipline end up with scattered flag checks, inconsistent default values, and evaluation logic that is impossible to unit test.
The canonical implementation pattern starts with defining a FlagProvider abstraction — an interface or protocol that the rest of the application calls for flag evaluation. This abstraction decouples application code from the specific flag backend (whether that is Firebase Remote Config, LaunchDarkly, Flagsmith, or a custom system). It also makes unit testing trivial: inject a MockFlagProvider in tests that returns deterministic values without any network dependency.
Production implementation workflow:
- Define a FlagProvider interface with typed evaluation methods (isEnabled, getStringValue, getNumberValue)
- Bundle a default flag manifest in the app binary as a JSON or properties file — this is the cold-start fallback
- On app launch, initialize the SDK with the bundled defaults, then trigger an async fetch of the remote configuration
- Persist fetched flag values to local storage and apply them on the next session (fetch-and-activate pattern)
- Pass an evaluation context (user ID, app version, device attributes) with every flag check to enable targeting
- Emit analytics events on flag evaluation to power experiment dashboards and observability pipelines
Example: FlagProvider interface (Kotlin)
interface FlagProvider {
fun isEnabled(key: String, context: EvalContext): Boolean
fun getString(key: String, context: EvalContext): String
fun getNumber(key: String, context: EvalContext): Double
}
data class EvalContext(
val userId: String,
val appVersion: String,
val locale: String,
val attributes: Map<String, Any> = emptyMap()
)
This abstraction pattern is consistent with the principles described in the Android architecture guidance for separating concerns across app layers. By containing all flag evaluation behind a single interface, you retain the ability to swap backends, run tests against a MockFlagProvider, and enforce that flag logic never bleeds into domain or data layers.
Advanced Patterns & Optimization
As feature flag usage scales across an organization, naive implementations reveal performance and correctness problems. The most common is evaluation latency: if flag checks require a network call, features that are gated behind flags introduce blocking operations in rendering paths and navigation transitions. The solution is local evaluation — all flag values should be resolved from an in-memory cache that is populated asynchronously. The SDK should expose a reactive or observable interface so that UI components can respond to flag changes without polling.
Experiment consistency is another area where advanced engineering is required. When a user is assigned to a treatment group in an A/B experiment, they must remain in that group for the duration of the experiment — even across app restarts, network gaps, and flag configuration updates. This requires a stable hashing function that maps (userId, flagKey, salt) to a deterministic bucket assignment. Most production SDKs handle this internally, but teams building custom systems must implement it deliberately. An experiment that silently reassigns users between treatment groups produces invalid statistical results.
For teams operating at significant scale, server-side evaluation with client-side delivery is worth considering. Instead of shipping the full ruleset to the client and evaluating there, the server evaluates flags for a given user context and returns only the resolved values. This approach reduces the attack surface for client-side flag inspection and keeps targeting rules confidential. The tradeoff is that every session requires a network round-trip to bootstrap the flag state, which means latency and reliability requirements shift to the server infrastructure.
Advanced optimization strategies:
- Local evaluation from in-memory cache — never block render or navigation on a flag network call
- Stable hash-based bucketing — ensures experiment assignment consistency across sessions and restarts
- Server-side evaluation for sensitive rules — keep targeting logic off the client for confidentiality
- Streaming flag updates — use WebSocket or SSE to push changes without polling overhead
- Flag evaluation batching — aggregate analytics events and send in batches to avoid per-evaluation network noise
Real-World Production Scenarios
Understanding how feature flags behave in specific production contexts is where engineering judgment becomes as important as technical knowledge. The following scenarios represent the most common and consequential use cases encountered in real mobile applications.
Scenario 1: Payment Flow Rollout
A team releasing a new payment provider integration needs to validate it against real transaction data before full exposure. They gate the new flow behind a flag and roll it out to 5% of users, monitoring payment success rates, error codes, and latency percentiles in their analytics platform. If metrics hold, they expand to 20%, then 50%, then 100% over a series of days. If a spike in declined transactions appears at 20%, they roll back by toggling the flag — no app update, no store review, no user-visible downtime. This scenario represents the highest-stakes use of feature flags and justifies the entire infrastructure investment on its own.
Scenario 2: Regional Feature Targeting
Some features are legally or commercially relevant only in specific markets. A digital wallet feature available only in select jurisdictions, a content recommendation module calibrated for a specific region, or a UI localization that depends on right-to-left text rendering — all of these require targeting flags that evaluate the user's locale or region attribute. Rather than shipping multiple binary variants, the team ships one binary and the flag system handles the routing. The evaluation context includes locale, country code, and optionally carrier or timezone, which the flag targeting rules evaluate server-side. For a deeper understanding of how platform locale APIs expose this data, the Apple Developer documentation on locale and internationalization is the authoritative reference.
Scenario 3: Canary Testing on Specific App Versions
When a new app version introduces a significant architectural change — a new navigation framework, a rewritten networking layer, or a migration to a new database schema — the risk is concentrated in the cohort running that version. Feature flags scoped to specific version strings let teams enable the new behavior only for users who have already updated to the version containing the relevant code. This version-scoped targeting is a frequent pattern in enterprise apps that need to maintain compatibility across a wide installed base with slow update adoption rates.
Scenario 4: Internal QA and Beta Environments
Feature flags eliminate the need for separate QA builds in many situations. By targeting flags to specific user IDs or email domains — for example, everyone at yourcompany.com — QA engineers and product managers can access unreleased features on production builds without those features being exposed to end users. This QA targeting approach, sometimes called internal user segments, is described in detail in the AppsOnAir guide to staging and production flag strategies. It collapses the staging-versus-production distinction for feature availability while keeping both environments on the same binary.

Common Pitfalls and Failure Patterns
Feature flag systems fail in ways that are predictable — and almost always related to organizational discipline rather than technical complexity. The most widespread failure pattern is flag accumulation: flags that were introduced for a specific release are never retired after that release completes. Over time, the codebase accumulates dozens or hundreds of conditional branches backed by flags that are permanently enabled or disabled but never cleaned up. This creates cognitive overhead, increases the surface area for bugs, and makes it impossible to reason about which code paths are actually executing in production. Teams that adopt feature flags without a flag lifecycle policy consistently run into this problem.
Another common failure is treating the default value as an afterthought. The default value is what the app evaluates when the SDK has not yet fetched remote configuration — this is the cold-start state, the offline state, and the state the app will be in during any network failure. If the default is not set deliberately and consistently, the app's behavior in offline mode will be undefined or, worse, will expose half-implemented features to users who happen to install the app without a network connection.
Evaluation performance is a pitfall that emerges at scale. A team that performs flag checks inside tight loops, inside RecyclerView bind methods, or inside hot rendering paths will see measurable frame drops when the evaluation logic becomes non-trivial. Flag evaluation should always resolve from a local cache and should never trigger I/O. Any implementation that calls a flag inside a loop without caching the result in a local variable is a latent performance bug.
The five most damaging pitfalls:
- Flag accumulation without retirement — stale flags become permanent code debt with undefined production behavior
- Undefined defaults — cold-start and offline behavior is unspecified when defaults are not deliberate
- Evaluation in hot paths — flag checks inside render loops or tight iteration without local caching
- Missing observability — enabling flags without dashboards makes it impossible to detect flag-correlated regressions
- Flag interdependencies — flags that depend on the state of other flags create combinatorial complexity and make behavior unpredictable
Strategic Best Practices
The most effective feature flag systems are not just technically well-implemented — they are organizationally well-governed. This means establishing clear ownership for each flag (which team is responsible for its lifecycle), defining a maximum acceptable flag age for release flags (typically tied to the release cycle length), and running periodic flag audits to retire stale configurations. Without this governance layer, even the best SDK integration becomes a maintenance burden within 12 months.
On the technical side, the most impactful best practice is the FlagProvider abstraction discussed in the implementation section. Any codebase that performs direct SDK calls at the call site rather than through an abstraction interface will be difficult to test and difficult to migrate if the backend changes. This is not premature abstraction — it is a minimum viable architecture for any system with more than a handful of flags. Testing a feature behind a flag should require only injecting a MockFlagProvider that returns the desired value; no network stubs, no remote state setup, no environment-specific configuration.
Observability is non-negotiable for any flag used in a production rollout. Every flag evaluation that gates a user experience should emit a tracking event with the flag key, the resolved value, the user ID, and the app version. This data feeds both the experiment analysis pipeline (for A/B tests) and the operational dashboard (for rollout health monitoring). Without this instrumentation, feature flag-driven releases are flying blind — teams cannot correlate a spike in crash rates or a drop in conversion with a specific flag activation.
Strategic best practices:
- Define a flag lifecycle policy with explicit retirement criteria for each flag type
- Always set explicit, safe default values — offline and cold-start behavior must be intentional
- Wrap all flag SDK calls behind a FlagProvider abstraction for testability and portability
- Instrument every production flag evaluation with analytics events for rollout observability
- Run flag audits quarterly — identify and retire any flag that has been fully enabled or disabled for more than one release cycle
- Avoid flag interdependencies — each flag should be independently evaluable without depending on the state of another flag
Conclusion
Feature flags let mobile teams release features safely, experiment quickly, and control behavior without app store updates.
They reduce risk and enable faster development, but only work well with discipline clear lifecycle management, testing, and monitoring.
Best practices include safe defaults, caching, consistent experiment bucketing, and secure evaluations.
Overall, they turn releases from risky big launches into controlled, gradual rollouts.










