


.svg)


Remote configuration has evolved from a convenience feature into a core engineering discipline. In teams operating at scale, the ability to alter app behavior without deploying a new binary is no longer optional — it is a fundamental requirement for safe releases, rapid experimentation, and operational resilience. Whether you are toggling a feature flag mid-rollout or adjusting a network timeout for a cohort of devices on flaky connections, the underlying system that makes this possible demands the same engineering rigor as your core product code.
What separates teams that use remote configuration well from those that merely use it is architecture. A poorly designed configuration system becomes a source of race conditions, stale data, silent failures, and developer confusion. An overly centralized one creates operational bottlenecks. Too permissive a schema becomes ungovernable within six months. The pro tips covered in this article address these failure modes directly — they are grounded in production realities, not theoretical ideals.
This article covers remote configuration from foundational concepts through advanced patterns, real-world scenarios, and strategic best practices. If you have already integrated a configuration SDK and are looking to go beyond the basics, this is the guide you have been looking for.
Foundational Concept: What Remote Configuration Actually Is
Remote configuration is the practice of externalizing application behavior parameters into a server-controlled key-value store that the app fetches at runtime. The simplest mental model is a dictionary your app reads on startup — but the correct mental model is a versioned, audience-segmented, cacheable contract between your backend and your client. The distinction matters because it changes how you design schemas, manage lifecycles, and reason about correctness.
The concept has its roots in feature flag systems and A/B testing infrastructure popularized by companies like Google and Facebook in the early 2010s. Firebase Remote Config, launched in 2016, brought this capability to the mainstream mobile developer audience. Since then the ecosystem has matured considerably: tools like LaunchDarkly, Unleash, Flagsmith, and Statsig offer sophisticated targeting, experimentation frameworks, and audit trails that go well beyond simple key-value retrieval.
In its current form, remote configuration typically involves three layers working in concert: a configuration service that stores and serves values, a client SDK that fetches, caches, and exposes those values, and an application layer that reads and acts on them. Each layer carries its own responsibilities and failure modes. Understanding the seams between them is where engineering expertise begins.
Key properties that define a well-designed remote configuration system:
- Determinism: given the same fetch context and timestamp, the app receives the same configuration.
- Audience targeting: values can differ by user cohort, app version, platform, or custom attributes.
- Caching with explicit staleness policies: network failures must not block app startup or degrade UX.
- Schema versioning: the contract between service and client must evolve without breaking deployed versions.
- Observability: every fetch, activation, and read should be traceable in your analytics pipeline.
Why It Matters in Modern Mobile Development
The mobile release cycle is structurally slower than the web. App Store and Play Store reviews add latency ranging from hours to days. Users who do not auto-update can remain on old binaries for months. These constraints make runtime configurability not just useful but strategically necessary. A critical bug in a payment flow, a misconfigured rate limit, or an overly aggressive feature rollout can be addressed immediately via remote configuration — without waiting for review, without forcing an update, and without touching infrastructure.
From a developer experience standpoint, remote configuration decouples deployment from release. Engineers can merge feature code behind a flag long before it is ready for users. QA can verify a feature in production by targeting a specific test account. Product managers can run controlled experiments. None of this requires a separate build. This separation of deploy and release is one of the most significant workflow improvements a mobile team can adopt, and remote configuration is its enabling mechanism.
Performance considerations are also non-trivial. The fetch-and-cache model means your app is not making synchronous network calls at every read. Properly configured, the cost of remote configuration at runtime is a single background fetch per session or interval, with all reads hitting an in-memory or on-disk cache. The challenge is making sure that model does not degrade under poor network conditions, and that the cache invalidation strategy aligns with your release cadence.
Where remote configuration delivers concrete engineering value:
- Kill switches: disable broken features instantly without an app update or rollback.
- Gradual rollouts: release to 1%, 10%, then 100% of users with automatic pause on elevated error rates.
- Dynamic thresholds: adjust timeouts, retry counts, and rate limits per environment without redeployment.
- Experiment scaffolding: run multivariate tests tied to analytics events without separate experiment SDKs.
- Environment targeting: serve staging URLs and debug overlays to internal builds automatically.
Architecture & System Design Breakdown
A production-grade remote configuration architecture is not simply "call the SDK on app start". It involves careful thinking about data flow, layering, fallback paths, and the separation of concerns between the configuration system and the application logic that consumes it. Collapsing these concerns leads to fragile code where business logic is entangled with network state management.
The recommended architecture introduces an abstraction layer — a ConfigurationRepository or ConfigProvider — that sits between the raw SDK and the rest of the application. This layer owns the fetch lifecycle, manages the in-memory representation, exposes typed accessors, and handles fallback logic. Application features never reference the SDK directly; they only interact with the abstraction. This makes testing trivial, SDK migrations non-breaking, and fallback logic centralized.
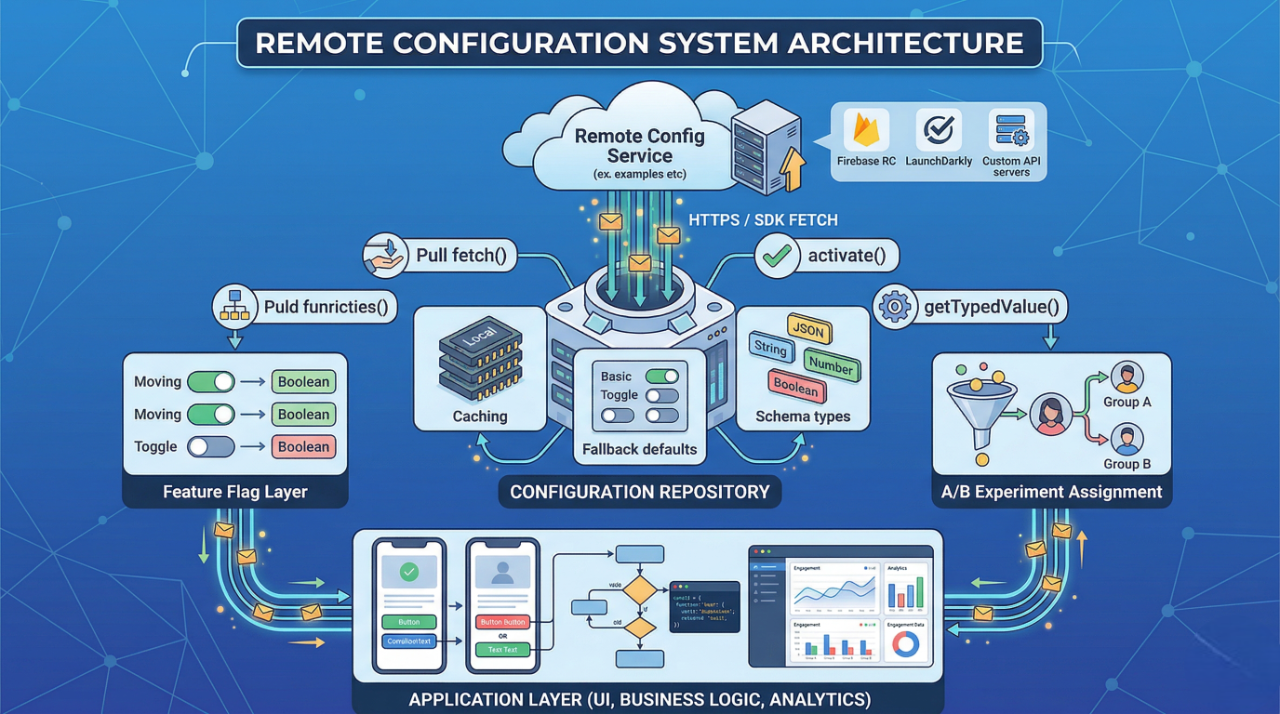
The configuration repository handles the three-state lifecycle that most SDK implementations expose: fetch (retrieve from network into temporary buffer), activate (promote buffer to active state), and read (consume active values). Conflating fetch and activate is one of the most common architectural mistakes — it causes mid-session configuration changes that produce inconsistent UI states. Activation should happen at a well-defined boundary: app foreground transition, session start, or explicit user action.
Implementation Deep Dive
Getting from SDK integration to a robust, production-ready implementation requires attention to six sequential concerns. Skipping or shortcutting any of them will surface problems at scale — typically manifesting as stale values, fetch storms, or untestable business logic.
- Define your schema first, in code. Create a strongly typed configuration model with explicit default values before you configure anything in the dashboard. Defaults are your contract — they must represent safe, production-valid states, not placeholder values.
- Implement the ConfigurationRepository abstraction. Inject the SDK behind an interface. This decouples your application from any specific vendor and makes unit testing possible without network calls or SDK initialization.
- Separate fetch from activate. Fetch on app background-to-foreground or on a timer. Activate only at session boundaries. Never activate mid-flow in response to a user action unless you have explicitly designed for dynamic reconfiguration.
- Apply exponential backoff on fetch failures. The SDK may handle this internally, but verify the behavior. A fetch storm caused by all clients retrying simultaneously after a service blip can degrade your configuration backend.
- Instrument every configuration read. Log which key was read, what value was returned, and whether it was a default or a fetched value. This data is essential for debugging and for correlating configuration changes with product metrics.
- Test with a mock ConfigurationRepository. Write unit tests that inject a fake repository returning controlled values. Never test configuration-dependent logic with live SDK calls — it couples your tests to network state and service availability.
A minimal typed accessor pattern in practice looks like the following. The configuration key is centralized, the return type is explicit, and the default is baked in — not scattered across call sites:
// Centralized schema definition
enum ConfigKey: String {
case checkoutFlowVariant = "checkout_flow_variant"
case maxRetryCount = "network_max_retry_count"
case enableNewFeedAlgo = "enable_new_feed_algorithm"
}
// Typed accessor in the repository
func bool(for key: ConfigKey, default fallback: Bool) -> Bool {
return remoteConfig[key.rawValue].boolValue
}
Advanced Patterns & Optimization
Once the fundamentals are solid, several advanced patterns emerge that significantly improve the reliability and capability of your configuration system. The most impactful ones address the challenges of multi-environment consistency, client-side targeting, configuration composition, and safe default management.
Client-side targeting deserves particular attention. Rather than relying entirely on the server to segment audiences, mature implementations allow the client to pass evaluation context — user attributes, device characteristics, session properties — and evaluate targeting rules locally. This eliminates a round-trip for flag evaluation and enables offline-compatible feature flagging. LaunchDarkly's client-side SDKs and OpenFeature-compatible implementations support this model natively. The tradeoff is that targeting logic must be synchronized to the client, which adds bundle size and requires careful version management.
Configuration composition — layering multiple sources with explicit priority — is another pattern worth implementing at scale. You might combine a local override file (for development), a cached remote fetch, and compile-time defaults, with a deterministic resolution order. This prevents the common situation where a developer cannot override a remote value during local debugging without modifying production configuration.
Advanced optimization points worth implementing in production systems:
- Conditional fetch intervals: increase fetch frequency post-release and reduce it once a version stabilizes to minimize unnecessary network activity.
- Hash-based cache invalidation: include a configuration hash in your activation check — only re-activate when the hash changes, not on every fetch.
- Background prefetch on app install: trigger a configuration fetch during onboarding or first launch so that subsequent sessions read from a warm cache.
- Stale-while-revalidate: serve the last-known-good configuration immediately, fetch updated values in the background, and apply them at the next natural activation boundary.
- Selective key subscriptions: in reactive architectures, expose configuration values as observable streams so that downstream components receive updates without polling.
Real-World Production Scenarios
Scenario 1: Emergency Kill Switch During a Live Incident
A payment provider integration begins returning errors at a rate that triggers your alerting threshold. The affected code is deep in a checkout flow that handles high transaction volume. A kill switch flag — enable_third_party_payment_provider — set to false routes all traffic to a fallback provider within seconds of the configuration change. No hotfix, no emergency review, no deployment. The critical design requirement: kill switches must activate within one fetch cycle, which means your fetch interval and activation boundary must be tuned for this use case. For incident response scenarios, consider a separate high-frequency polling channel for critical flags distinct from your standard configuration fetch.
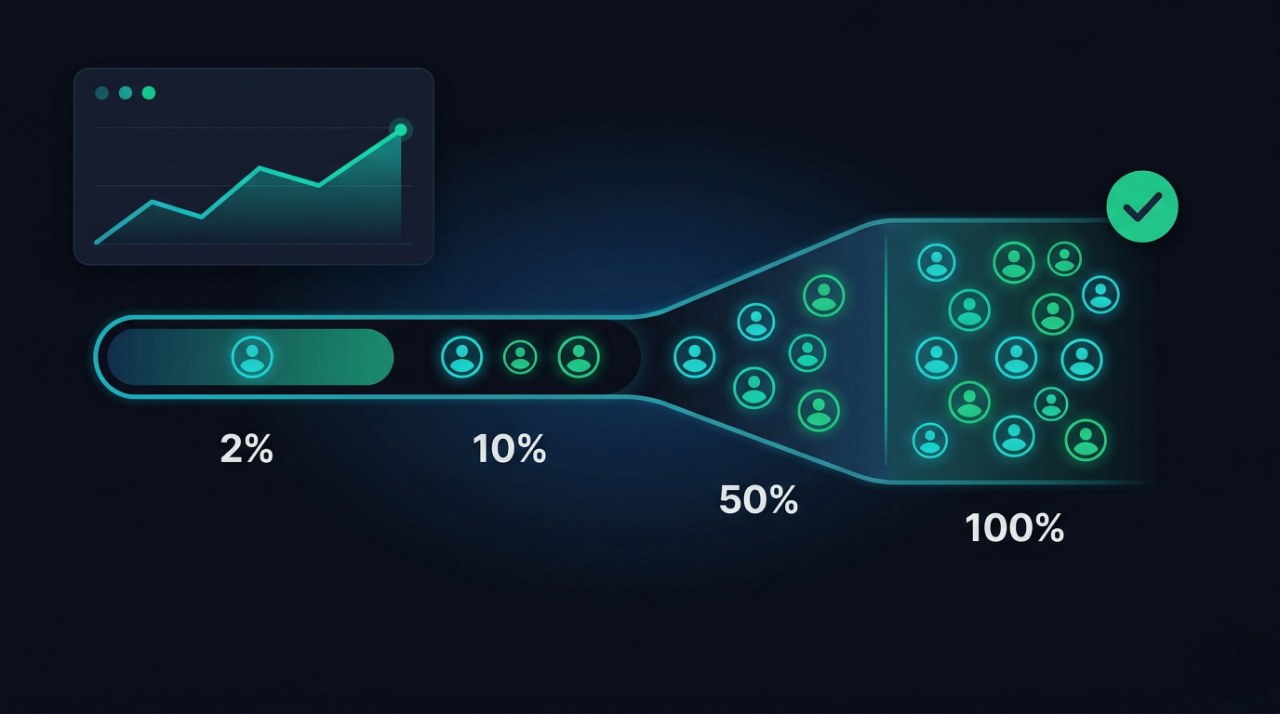
Scenario 2: Percentage-Based Feature Rollout with Automatic Pause
A new feed ranking algorithm is ready for release. Rather than shipping it to all users simultaneously, you configure a gradual rollout: 2% for 24 hours, 10% for 48 hours, then 50%, then 100%. Your analytics pipeline monitors crash rates and engagement metrics for the treatment cohort against the control. If the crash rate delta exceeds a threshold, the rollout configuration is automatically reverted by a monitoring script that writes to the configuration API. This is not a hypothetical — it is a standard pattern in mature mobile organizations. The configuration system is the control plane; your observability stack is the feedback loop.
Scenario 3: Per-Environment Configuration Without Separate Builds
A single app binary ships to App Review, internal testers, and production users. Rather than using build flags to differentiate environments — which requires separate binaries — you use remote configuration to serve environment-specific values based on a user attribute set during authentication. Internal accounts receive staging API URLs, verbose logging flags, and debug overlay toggles. App Review builds receive production URLs but with test account seeding flags enabled. This reduces build complexity, eliminates the risk of submitting the wrong binary, and allows environment behavior to change without a rebuild.
Scenario 4: Dynamic Theming and Copy Management
Marketing needs to update a promotional banner headline for a time-limited campaign. Normally this would require a content update, App Store review, and a push notification strategy. With remote configuration, the headline string, CTA copy, and campaign end timestamp are all server-controlled. The app reads them at session start and renders accordingly. The product team can update copy in real time, schedule campaigns via the configuration dashboard, and A/B test messaging variants — all without involving engineering beyond the initial instrumentation.
Common Pitfalls and Failure Patterns
Remote configuration failure patterns are rarely dramatic. They tend to be subtle: the app behaves slightly incorrectly for a subset of users, or a configuration change has no visible effect, or a flag that should have been removed months ago is still gating 15% of users from a fully-shipped feature. These failures accumulate over time and degrade both product quality and team confidence in the configuration system.
The most damaging failure pattern is treating configuration as a deployment mechanism for logic rather than for values. When engineers start encoding business rules as configuration strings that the app evaluates — such as serialized conditional logic, JSON-encoded workflows, or dynamic SQL fragments — the configuration system becomes an unversioned, untested, invisible code path. Bugs in these "code in config" patterns are nearly impossible to reproduce locally, invisible to static analysis, and catastrophic when malformed.
Schema drift is another systemic failure. Without a registry of active keys, their types, their owners, and their retirement dates, configuration namespaces accumulate dead keys indefinitely.
Five failure patterns to watch for:
- Fetch-activate conflation: activating fetched values immediately, causing mid-session configuration changes and UI inconsistency.
- Missing defaults: relying on the SDK to return a safe zero-value when a key is absent instead of declaring an explicit, tested default.
- Blocking app startup on fetch: making the first fetch synchronous causes cold start degradation and renders the app non-functional when the configuration service is unavailable.
- Unbounded key growth: no governance process for retiring deprecated keys leads to namespace pollution and maintenance debt.
- Insufficient observability: not tracking which configuration values were active when a bug occurred makes incident post-mortems nearly impossible.
Strategic Best Practices
The best practices for remote configuration operate at two levels: technical hygiene and organizational process. Technical hygiene addresses how you build the system; organizational process addresses how you govern it. Both are necessary. A technically excellent system that no one governs will degrade. A well-governed system built on a fragile technical foundation will fail under operational pressure.
From a technical standpoint, the single highest-leverage practice is establishing a typed schema registry as the source of truth for all configuration keys. This registry defines the key name, value type, default value, owning team, creation date, and retirement date for every key in use. It should be version-controlled alongside application code and reviewed as part of the PR process for any configuration change. This is the architectural foundation that enables safe key removal, cross-team coordination, and configuration auditing.
On the organizational side, configuration changes should follow the same review discipline as code changes. A dashboard edit that disables a feature for 30% of users is a production change. It deserves a review, a documented rollback plan, and a monitoring window. Teams that apply rigorous engineering practices to code but treat configuration dashboards as informal scratch pads will eventually experience a configuration-caused incident that a code review process would have prevented.
Six best practices for production-grade remote configuration:
- Maintain a version-controlled schema registry: every key should have a declared owner, type, default, and planned retirement date.
- Never block app launch on a configuration fetch: always initialize from cached or default values and update asynchronously.
- Instrument configuration reads in your analytics pipeline: correlate active configuration values with product metrics for every experiment and rollout.
- Define and test your fallback path explicitly: simulate configuration service outages in your staging environment to verify that the app behaves correctly with defaults.
- Apply the same review discipline to configuration changes as to code changes: treat dashboard edits as production deployments.
- Retire flags promptly: set calendar reminders at rollout time to remove the flag and its associated code once a feature reaches 100% of users.
Conclusion
Remote configuration is a powerful tool in mobile engineering, but its effectiveness depends on strong architecture and disciplined governance—not just the tools used. High-performing teams treat it as a core infrastructure layer, applying best practices like typed schemas, abstraction layers, caching strategies, and clear ownership of configuration keys.
When designed properly, remote config systems remain scalable, reliable, and maintainable. When handled poorly, they lead to hidden failures and growing technical debt. These practices can be adopted gradually, with increasing benefits as teams and release frequency grow.
Key takeaway: Remote configuration isn’t just a feature—it’s infrastructure. Investing in its design enables safer releases, faster experimentation, and better incident response, regardless of the backend tool used.










